Everything that the AWS S3 Can Do!

I'm deeply passionate about cloud computing and DevOps, driven by an insatiable curiosity to master cutting-edge technologies. From AWS to Docker, Kubernetes, Jenkins, Linux, Git, and Terraform, I thrive on exploring and pushing the boundaries of what's possible. Beyond the code, I believe in the power of collaboration and shared learning experiences. With each interaction, I cherish the opportunity to grow together and build meaningful connections. As I embark on this exciting journey, I'm eager to contribute my expertise and bring a human touch to the ever-evolving landscape of cloud and DevOps.
AWS Simple Storage Service (S3) can do a lot of things besides storing the data. I used the term data instead of files because at core the AWS S3 is an Object Store and not a File Store, I will explain this more in the later section.
AWS S3 is an amazing service from Amazon, no doubt about that. It contains many many features, which even a regular user might miss. AWS keeps adding new features to S3 from time to time, and I am going to list out most of them (if not all) in this post.
Let’s Start
We will explore different sections of S3 one by one, from storage to security and how organizations use S3 for different use cases.
Storage
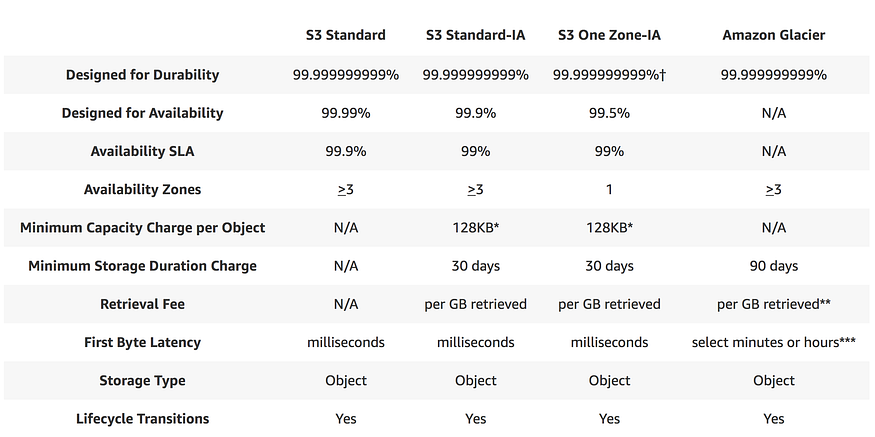
S3 offers total four class storage solutions, with unlimited data storage capacity:
S3 Standard
S3 Standard Infrequent Access (otherwise known as S3 IA)
S3 One Zoned Infrequent Access
Glacier
Amazon S3 Standard
S3 Standard offers high durability, availability, and performance object storage for frequently accessed data. Because it delivers low latency and high throughput. It is perfect for a wide variety of use cases including cloud applications, dynamic websites, content distribution, mobile and gaming applications, and Big Data analytics.
For example, a mobile application collecting user photo uploads. With unlimited storage, there will never be a disk size issue. S3 can also eliminate unsuccessful uploads, one less thing to worry about cleanup.
S3 Infrequent Access (IA)
S3 IA is designed for data that is accessed less frequently but requires rapid access when needed. S3 Standard-IA offers the high durability, high throughput, and low latency of S3 Standard, with a low per GB storage price and per GB retrieval fee. This combination of low cost and high performance make S3 Standard-IA ideal for long-term storage, backups, and as a data store for disaster recovery.
For example, a mobile application for collecting user photo uploads on daily basis, soon some of those photos will go out of access need like there will be less demand to see 6-month-old photos. With IA we can move the objects to different storage class without affecting their durability. Changing the storage class from Standard to IA is a simple configuration, and can be done easily with Lifecycle Management.
S3 One Zoned-IA
S3 One Zoned-IA is designed for data that is accessed less frequently but requires rapid access when needed. Unlike other storage classes, which store data in a minimum of three Availability Zones (data centers), S3 One Zone-IA stores data in a single AZ. Because of this, storing data in S3 One Zone-IA costs 20% less than storing it in S3 Standard-IA. It’s a good choice, for example, for storing secondary backup copies of on-premises data or easily re-creatable data.
S3 Reduced Redundancy Storage
Reduced Redundancy Storage (RRS) is an Amazon S3 storage option that enables customers to store noncritical, reproducible data at lower levels of redundancy than Amazon S3’s standard storage.
Amazon Glacier
Amazon Glacier is a secure, durable, and extremely low-cost storage service for data archiving. Customers can store data for as little as $0.004 per gigabyte per month. To keep costs low yet suitable for varying retrieval needs, Amazon Glacier provides different options for access to archives, from a few minutes to several hours.
Availability and Durability
When we look for any service to integrate into our application, the major thing we look for is the reliability (and durability) of the service? How frequently the service goes down and what happens to our data if something goes wrong? To keep those things in mind, I am going to list out S3 availability and durability standards first, before we dive into the other features.
S3 Standard offers 99.99% availability and 99.999999999% durability (Yes, that many 9s)
S3 IA offers 99.9% availability and 99.99% durability
S3 One Zoned-IA offers 99.5% availability and 99.999999999% durability, but data will be lost in the event of Availability Zone destruction (data center site failure)
Glacier offers 99.99% availability and 99.999999999% durability
S3 RRS is designed to provide 99.99% durability and 99.99% availability
Amazon S3 as a Backbone for Static Websites
Static website hosting: Amazon S3 directly serves static files, offering a simple and cost-effective solution for hosting websites with scalability and availability.
Content delivery: Integration with Amazon CloudFront ensures fast and reliable delivery of website content globally, improving performance for users.
Scalability and durability: Amazon S3’s scalable infrastructure handles high traffic loads while maintaining performance, and its distributed architecture provides durability by storing multiple copies of website content.
Cost-effectiveness: With a pay-as-you-go pricing model, Amazon S3 is a cost-effective option for hosting websites, especially for static content with predictable traffic patterns.
Integration with AWS services: Amazon S3 seamlessly integrates with other AWS services, empowering the creation of dynamic and interactive websites by leveraging additional capabilities like AWS Lambda, Amazon API Gateway, and Amazon CloudFront
Amazon S3 Use cases
Backup and Storage: Reliable and scalable storage for data backups.
Disaster Recovery: Replicating data to ensure accessibility during disasters.
Archive: Cost-effective storage for infrequently accessed data.
Hybrid Cloud Storage: Integration of on-premises and cloud storage.
Application Hosting: Hosting static web content and web applications
Media Hosting: Storing and delivering media files with high-performance
Software Delivery: Efficient distribution of software updates and applications
Static Website: Hosting static websites with scalability and reliability.
Amazon S3 — Buckets

Bucket Purpose: Amazon S3 allows users to store objects (files) in “buckets,” which can be thought of as directories within the S3 service
Global Unique Name: Each bucket must have a globally unique name across all regions and accounts. This uniqueness ensures that there are no naming conflicts and enables proper identification of each bucket.
Region Level Definition: Buckets are defined at the region level, meaning that when you create a bucket, it is associated with a specific AWS region. Although S3 appears to be a global service, buckets are created and exist within a particular region.
Naming Format: When naming a bucket, it should adhere to the following conventions:
No uppercase letters or underscores are allowed in bucket names.
The name must be between 3 and 63 characters in length.
The bucket name cannot be an IP address.
It must start with a lowercase letter or a number.
The bucket name must not start with the prefix “xn — “.
It must not end with the suffix “-s3alia”.
These naming guidelines ensure consistency, uniqueness, and compatibility within the Amazon S3 service. Adhering to these rules will prevent naming conflicts, maintain the integrity of the S3 infrastructure, and facilitate a smooth operation and management of your buckets.
Amazon S3 — Objects

In Amazon S3, objects (files) are identified by their keys, which represent the full path to the object.
For example:
s3://my-bucket/my_file.txt
s3://my-bucket/my_folder1/another_folder/my_file.txt
The key of an object is composed of a prefix and the object name. In the second example above, the prefix is “my_folder1/another_folder/” and the object name is “my_file.txt”.
It’s important to note that although the Amazon S3 user interface may visually represent objects as if they are organized in directories within buckets, there is actually no concept of directories within buckets. Instead, objects have keys with very long names that can include slashes (“/”) to mimic the appearance of a directory structure.
Amazon S3 — Objects (cont.)

In Amazon S3, object values are the content of the object

The maximum object size is 5TB (5000GB).

For uploads larger than 5GB, multipart upload should be used.

Objects can have metadata, which is a list of text key/value pairs, and tags, which are Unicode key/value pairs (up to 10 tags).

If versioning is enabled, objects can have multiple versions identified by unique version IDs
now , it’s very crucial to see the security features as well.
Amazon S3 — Security

User-Based:
Amazon S3 employs IAM Policies to control which API calls are permitted for specific users from IAM.

Resource-Based:
Bucket Policies, configured through the S3 console, establish bucket-wide rules, including the ability to enable cross-account access.

Object Access Control List (ACL):
Offers finer-grained access control for S3 objects, which can be disabled if needed.

Bucket Access Control List (ACL):
Although less common, it provides access control at the bucket level and can also be disabled.

Important Note:
An IAM principal can access an S3 object if the user’s IAM permissions or the resource policy allows it, as long as there is no explicit denial.

Encryption:
Amazon S3 allows encryption of objects using encryption keys for added security
S3 Bucket Policies
JSON-based policies:
S3 bucket policies are written in JSON format.
Resources:
Bucket policies apply to both buckets and objects within them.
Effect:
Policies can have “Allow” or “Deny” effects on access.
Actions:
Policies define a set of API actions to allow or deny.
Principal:
Specifies the AWS account or user to apply the policy to.
Common uses of bucket policies include granting public access, enforcing object encryption at upload, and allowing access to another account (cross-account access).

Example: Public Access — Use Bucket Policy
To grant public access to an S3 bucket, you can use a bucket policy.

In this example, the policy allows anyone (“Principal”: “”) to perform the “s3:GetObject” action on any object within the specified bucket (“Resource”: “arn:aws:s3:::your-bucket-name/”). This effectively grants public read access to the bucket.

Example: User Access to S3 — IAM Permissions
To control user access to S3 resources, you can define IAM permissions. Here’s an example:

In this example, the policy allows a user to list the bucket contents(s3:ListBuckets) and perform read and write operations (s3:Getobjects, s3:Putobjects) on objects within the specified bucket (arn:aws:s3:::your-bucket-name/*).

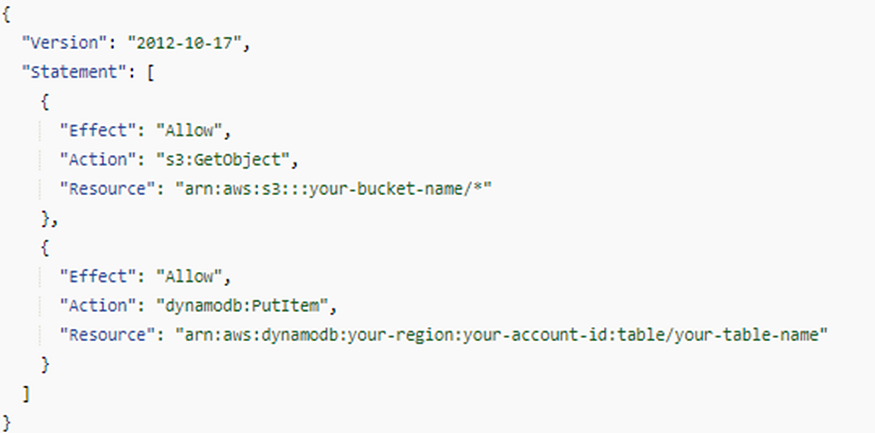
Example: EC2 instance access — Use IAM Roles
To grant EC2 instances access to AWS services, you can use IAM roles. Here’s an example:
Create an IAM role with the required permissions.

In this example, the IAM role grants permissions for the EC2 instance to perform the “s3:GetObject” action on objects within the specified S3 bucket (“arn:aws:s3:::your-bucket-name/*”) and “dynamodb: PutItem” action on the specified DynamoDB table (“arn:aws:dynamodb:your-region:your-account-id:table/your-table-name”).
Bucket settings for Block Public Access
Prevents Data Leaks:
Bucket settings for Block Public Access are designed to prevent accidental exposure of company data.
By blocking public access, the risk of unauthorized access and data leaks is significantly reduced.
Keep Settings Enabled:
If you are certain that your bucket should never be public, it is advisable to keep these settings enabled.
This ensures that your data remains secure and inaccessible to the public.
Account-Level Configuration:
Block Public Access settings can be set at the account level.
This provides consistent security measures across all buckets within the account.
By implementing and maintaining the Block Public Access settings for your S3 buckets, you can effectively mitigate the risk of data leaks and unauthorized access, ensuring the confidentiality and security of your company’s data.
Amazon S3 -Versioning
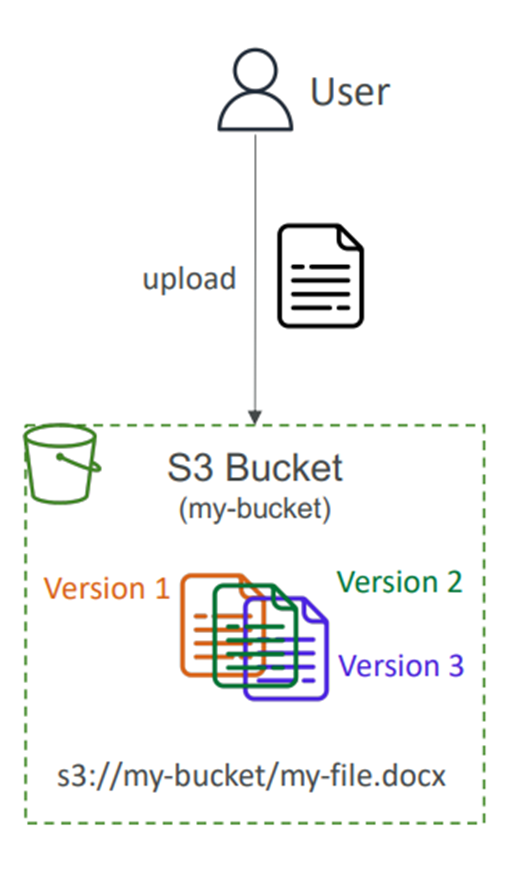
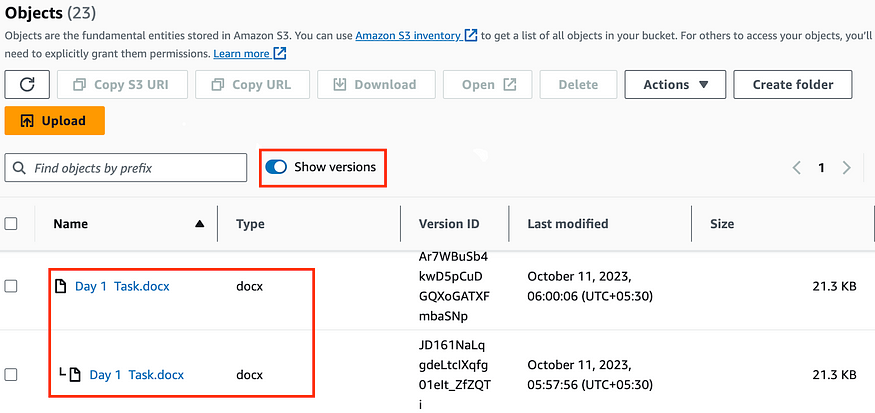
Versioning in Amazon S3 allows you to track and manage versions of your files.
It is enabled at the bucket level and assigns version numbers to files.
Versioning is considered a best practice to protect against unintended deletes and enables easy rollback to previous versions.
Enabling versioning does not delete previous versions, and any non-versioned files will have a version number of “null.”
Conclusion
We have explored some of the fundamental details of Amazon S3. I believe what we have covered in this article is enough to get you started using the service and also to help you make well-informed business decisions when it comes to choosing an S3 storage option based on cost, performance or use case. Go on and keep exploring this service so that you can enjoy the benefits it offers. Be sure to leave any questions you have in the comment section.




